
Codex casts wide search nets while Claude Code reads file by file. Same task, different exploration paths.
Coding agents spend most of every session on exploration: the search-read-decide loop that runs before any code gets written and never appears in the output. It determines API call count, per-call context size, dollar cost, latency, and whether the agent finds everything it should. Different agents handle it very differently, and each one’s pattern carries over to any task it takes on, code or otherwise.
We measured exploration for Codex (GPT-5.4 and GPT-5.4 mini) and Claude Code (Opus 4.6 and Sonnet 4.6) in a controlled environment from our prior work. Each agent had to find every passage of a Wikipedia article (say, Banks) among 5,164 randomly-numbered markdown files. 60 episodes per variant, ground truth known up front, every tool call logged.
Four findings
- The tool shapes the strategy. Codex’s
rg -nreturns matched lines with content inline. Claude’sGrepreturns filenames only, andReadopens one file at a time. This one difference in tool design accounts for Codex’s 5× larger per-call context and Claude’s 4× higher API call count on the same task.- Codex costs more per episode than Claude, despite OpenAI’s lower per-token rate. Across 15 episodes, Codex averages $1.63 versus Claude’s $1.24. Codex’s larger per-call context inflates billed input tokens, and Claude’s cache-read discount (10% of fresh-input rate) is steeper than Codex’s (25%).
- Turn the reasoning dial up before reaching for a bigger model. On weaker models, the effort dial moves recall by 12–13 pp (Sonnet 4.6, GPT-5.4 mini, low to max). Picking the flagship at the same effort moves it less. Most users leave the dial on default.
- Weak runs share one pattern: the agent quits with the next step in plain sight. A search returns candidate files, the agent never opens them. A keyword misses, the agent never tries another. A plan names the next step, the agent skips it. Both flagships at max effort never do this. Sonnet 4.6 and GPT-5.4 mini at low effort do, in over a fifth of episodes.
How we set up the experiment
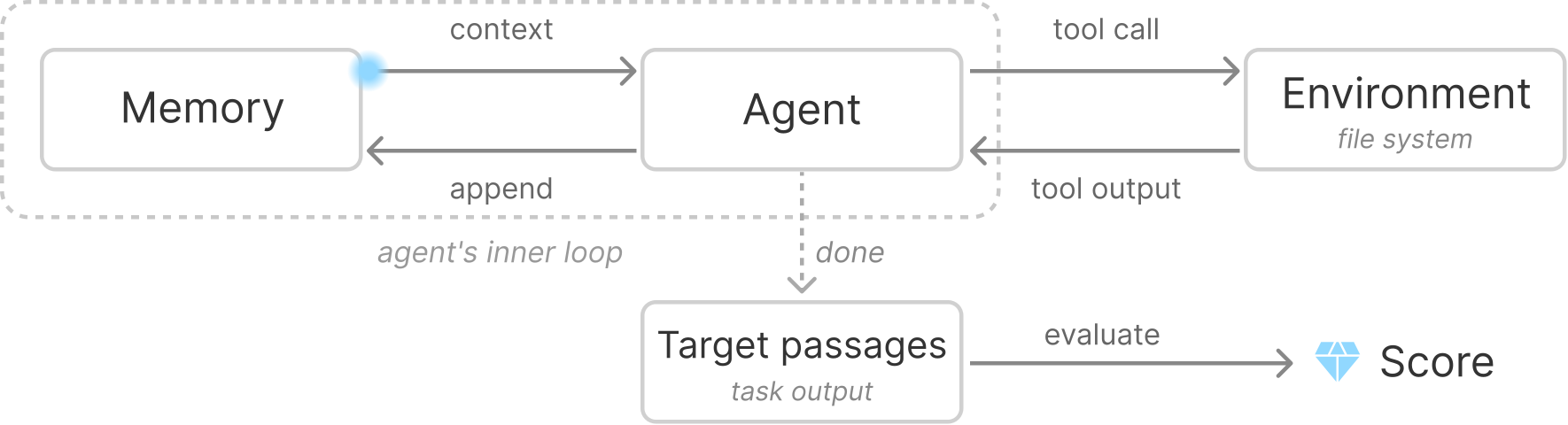
The agent’s search-read-update loop. At each step, the agent’s memory feeds context to the LLM, which issues a tool call to the file system; the tool output flows back into memory, and the cycle repeats. When the loop ends, the agent submits Target passages as its answer, which we then evaluate for a Score.

A snapshot of the agent’s context at an arbitrary step t, shown for the Banks article. Each turn —
Task,Agenttext + tool calls, andTool resultblocks — is appended to memory as the loop runs. Earlier turns are omitted for brevity.
We ran both agents through SeekerGym, a controlled exploration environment from our prior work. Each agent saw the same 5,164 markdown files (one per Wikipedia passage, randomly numbered so file order gives no structural hint) and was asked to find all passages belonging to each of 30 target articles. Both agents ran in their native configurations with no harness modifications. Web search was blocked so all exploration happened inside the corpus. Everything ran locally on a MacBook M4.
Full methodology + corpus construction
Why a controlled environment. Real coding sessions vary too much to compare fairly. Different users use these agents for different purposes (planning, executing, writing, researching), the codebases differ, and each user’s style shapes how the agent behaves. We needed a setup where both agents face the same challenge in the same environment with no user variation.
SeekerGym in brief. SeekerGym (arXiv:2604.17143) is a controlled text exploration environment built on Wikipedia. It gives the agent the same kinds of search/read tools it uses for coding (rg, grep, cat, file navigation), but in a domain where information gathering can be measured precisely against a known ground truth.
The corpus. We took the SeekerGym Wikipedia dataset (120 articles across 15 topic clusters) and converted all 5,164 non-abstract passages into individual markdown files. Every passage became a standalone file named with a generic number (0001.md through 5164.md), randomly shuffled so file ordering gives no structural hints. The agent starts in this flat directory of 5,164 files, receives a topic name and abstract, and must find all passages belonging to that article among thousands of distractors from other topics.
What we measured. Recall (% of target passages found), precision (% of reads that were targets), tool calls per episode, files read per call, peak per-turn context size, and total episode wall-clock time. Each (model, effort) variant ran 30 articles with 2 random seeds each, for 60 episodes per variant.
Exploration profiles of Codex and Claude Code
Both agents were asked to find every passage of the Banks article (37 target passages). The cursor blink before each command is the model’s reasoning time, scaled to real wall-clock proportions. Codex’s first 10 tool calls reach 89% completeness in the real episode. Claude Code’s first 22 tool calls reach 27%. Both agents eventually find all 37 targets in their full episodes (Codex: 38 total calls, Claude Code: 74).
Codex’s pattern: search-that-reads. GPT-5.4’s signature move is rg -n, which scans all 5,164 files and returns matched lines with their content inline. One tool call does both search and read. This single pattern accounts for more than half of Codex’s tool calls per episode. Each call surfaces new content, the agent spots new keywords in what came back, and feeds them into the next search. The loop compounds quickly, which is why Codex hits 90%+ completeness in only a handful of API calls.
Claude’s pattern: alternating Grep and Read batches. Opus’s rhythm is different. A search phase first (3–6 parallel Greps that return only filenames), then a content phase (6–8 parallel Reads on the candidates). No single tool both searches and reads. The separation forces the agent to commit to a candidate set before opening anything, which keeps precision high but takes more API calls overall.
The actual tools each variant reaches for split sharply by family. Codex’s shell-based agents concentrate on rg and sed. Claude’s tool-typed agents use Read and Grep. Sonnet is the one variant that frequently falls back to Bash for-loops when its native Read+Grep pattern doesn’t suffice.
| Command | GPT-5.4 | 5.4 mini | Opus 4.6 | Sonnet 4.6 |
|---|---|---|---|---|
rg -n (returns matched lines + content) | 43% | 6% | — | — |
rg -l (returns filenames only) | 10% | 18% | — | — |
sed -n 'A,Bp' (read line range) | 18% | 63% | — | — |
Read (open one file) | — | — | 55% | 22% |
Grep -l (returns filenames only) | — | — | 45% | 63% |
for f in ...; do ...; done (batch) | 6% | 6% | <1% | 9% |
cat (full file read) | <1% | <1% | <1% | 3% |
Other (find, ls, printf, etc.) | 23% | 7% | <1% | 2% |
The two-pattern split holds across model size and reasoning effort. Run the same task with smaller models or lower effort, and the same divergence shows up in recall and precision.

Average recall and precision across 30 articles per (model, effort) variant. Error bars show ±1 stdev across articles. All variants reach similar recall (~85–95%), but precision diverges sharply. Codex spends many reads on non-target files (broad sweep), while Claude Opus stays close to target reads only (ideal). *OpenAI labels max-reasoning
xhigh. We display “max” for parity with Anthropic.
The two agents reach similar recall but along very different paths. Codex casts wide nets and converges on high recall in fewer API calls, at the cost of low precision (many non-target files read). Claude Opus moves through more API calls, each surfacing a narrower slice of content, and ends up closer to the precision-recall ideal corner.
Detailed numerics + tool granularity
The four flagships at a glance. Averages across 60 episodes per variant (30 articles, 2 seeds each). Recall and precision are measured over the agent’s read set rather than its submitted answer.
| Variant | LLM calls | Tool calls | Tools / call | Files read | Recall | Precision |
|---|---|---|---|---|---|---|
Codex GPT-5.4 (max) | 9.5 | 29.5 | 3.1× | 132 | 95.5% | 42.5% |
Codex GPT-5.4 (low) | 5.5 | 12.1 | 2.2× | 71 | 86.7% | 60.5% |
Claude Opus 4.6 (max) | 28.9 | 112.5 | 4.0× | 64 | 95.4% | 71.1% |
Claude Opus 4.6 (low) | 16.5 | 38.6 | 2.0× | 52 | 91.6% | 78.8% |
The gap is in tool granularity, not LLM-level parallelism. Both agents dispatch multiple tool calls per LLM decision (Codex about 3×, Claude Opus 4.6 about 4× at max effort). The big difference is what each tool surfaces. Each Codex tool call reads about 4–5 files of content on average (driven by rg -n returning matched lines from many files at once). Each Claude tool call reads about 0.6 files (Grep returns filenames only, Read opens one file at a time). On the same task, the broader-per-tool pattern is what produces Codex’s much larger file-read total despite far fewer tool calls.
Which agent costs less to run?
What counts as “efficient” depends on what you measure. Codex makes fewer API calls than Claude Code. By per-call context size, wall-clock time, and dollar cost, the picture shifts.

Each point is one episode, run locally on a MacBook M4. Codex clusters at 150–500K tokens of peak context, Claude Opus at 30–80K. Episode durations overlap substantially.
Codex sends much more content to the model on every call. Each Codex API call carries hundreds of thousands of tokens of retrieved file content, the side effect of broad rg queries plus batch reads. Claude keeps each call lean. Median peak context is roughly 273K tokens for Codex GPT-5.4 versus 49K for Claude Opus, a 5.5× gap on the same task. Irrelevant files compete with relevant ones for attention inside that context, which is the measurable consequence of Codex’s lower precision.
Wall-clock time evens out. Codex makes about 4× fewer API calls (around 7 per episode versus around 30 for Claude), but each Codex call costs ~40 seconds (heavy reasoning plus waiting on a parallel batch of bulk tools). Each Claude call costs ~10 seconds. The ratio cancels, and total episode time is comparable. By median, Claude is actually a touch quicker (268s versus 299s).
Codex’s lower per-token rate does not translate into a lower bill. A smaller call count might suggest a smaller total cost, but the opposite holds. Across 15 episodes, Codex averages $1.63 per episode and Claude averages $1.24, despite Opus charging higher list prices per token ($5/M input versus $2.50/M for Codex). Two effects compound. Codex’s much larger per-call context piles up billable input tokens even at OpenAI’s lower rate, and Claude’s prompt caching absorbs most of its input volume at a steeper discount than Codex’s caching offers.
So Codex’s broad sweep is faster only if you measure in API calls. By context budget, wall-clock, or dollars, the picture is even or favors Claude. Which agent is more efficient depends on which bottleneck you actually hit.
Pricing methodology + per-episode tables
Per-episode cost.
| Variant | Per-episode avg | Per-episode median | Total (15 eps) |
|---|---|---|---|
Codex GPT-5.4 (max) | $1.63 | $1.55 | $24.46 |
Claude Opus 4.6 (max) | $1.24 | $1.02 | $18.62 |
Prices as of 2026-04-18. Codex totals computed from total_token_usage in session logs against OpenAI list pricing ($2.50/M input, $0.625/M cached input at the 25% discount, $15/M output). Claude is reported directly by Anthropic billing via total_cost_usd ($5/M fresh input, $0.50/M cache-read, $6.25/M cache-creation, $25/M output).
Why Codex is more expensive despite the lower per-token rate. Two effects compound. First, Codex’s much larger per-call context (~273K peak tokens versus ~49K for Claude) piles up billable input tokens even at the lower per-M rate. Second, Claude’s prompt caching (cache-read at 10% of fresh-input rate) absorbs most of its input volume, while Codex’s cached-input discount is shallower (25% of input rate).
Latency math. Codex GPT-5.4 (max) averages ~10 LLM calls per episode at ~28s each. Claude Opus 4.6 (max) averages ~29 LLM calls at ~10s each. Total wall-clock is comparable, with Codex averaging 282s (median 299s) and Claude averaging 302s (median 268s).
Why Codex needs fewer LLM calls
The headline difference in API call counts (Codex needs ~7 LLM calls to reach 90% recall, Opus needs ~28) does not come from one agent searching harder. It comes from each LLM call doing different amounts of work along the way. Two things vary across models.
Each marker represents one averaged LLM call. Codex GPT-5.4 reaches 90%+ completeness in ~7 API calls at
maxreasoning. Claude Opus converges around ~30 API calls. Y-axis truncated at 40% to focus on convergence behavior.
The numbers behind those curves split into two parts.
| Family | Variant | LLM calls | Tools / call | Files / call |
|---|---|---|---|---|
| GPT | GPT-5.4 (max) | 9.5 | 3.1× | 13.8 |
| GPT | GPT-5.4 (low) | 5.5 | 2.2× | 13.4 |
| GPT | GPT-5.4 mini (max) | 17.6 | 3.6× | 6.6 |
| GPT | GPT-5.4 mini (low) | 5.2 | 3.5× | 11.3 |
| Claude | Opus 4.6 (max) | 28.9 | 4.0× | 2.2 |
| Claude | Opus 4.6 (low) | 16.5 | 2.0× | 3.9 |
| Claude | Sonnet 4.6 (max) | 30.2 | 1.4× | 2.6 |
| Claude | Sonnet 4.6 (low) | 11.3 | 0.9× | 5.9 |
Tools per call counts how many tool invocations the agent dispatches in one round. This is the call-level parallelism the agent’s planner controls. The dial works the way you’d expect, with Opus 4.6 at max packing 4× while Sonnet 4.6 at low runs essentially sequentially at 0.9×. The Claude family tracks this dial more visibly than the GPT family does. GPT-5.4 stays in a 2 to 3.6× band across model and effort.
Files per call counts how many files of content come back from those calls. This is what determines whether the LLM call actually learns much. Codex GPT-5.4 at max surfaces about 12.7 files of content per round. Opus at the same effort surfaces about 2.2, a 5–6× gap on identical tasks. The reason is tool granularity. rg -n returns matched lines along with their surrounding content from many files in one shell call, so one Codex tool call can inspect 4 to 5 files of content at once. Claude’s Grep returns filenames only and Read opens one file at a time, so each Claude tool call surfaces about 0.6 files. This is what drives Codex reaching 90% completeness in around 7 LLM calls while Opus needs about 28.
Reasoning effort beats model size
Within a family, larger models do reach higher recall. The reasoning-effort dial moves recall more in most cases. Both Codex and Claude Code let you turn up how much the model thinks before each response, and that gives a bigger lift than picking a stronger model at the same effort. The gap is widest for the smaller models in each family.
| Model | Recall (low) | Recall (max) | Δ from low → max |
|---|---|---|---|
| GPT-5.4 | 86.7% | 95.5% | +8.8 pp |
| GPT-5.4 mini | 79.3% | 91.3% | +12.0 pp |
| Opus 4.6 | 91.6% | 95.4% | +3.8 pp |
| Sonnet 4.6 | 79.6% | 93.0% | +13.4 pp |
Effort wins for the smaller models. Sonnet picks up 13 percentage points of recall when effort goes from low to max. GPT-5.4 mini picks up 12. The big jumps live where the model has the most to lose by giving up early.
For the flagship models, the effort lift is smaller but still real. GPT-5.4 gains 9 pp, Opus 4.6 only 4 pp. Opus 4.6 at low effort already reaches 92%, so there is less room to grow.
Picking a smaller model at the same effort costs less than dropping the effort dial on the same model. Going GPT-5.4 (max) → GPT-5.4 mini (max) loses 4.2 pp. Going GPT-5.4 (max) → GPT-5.4 (low) loses 8.8 pp. The same pattern holds in the Claude family for the max variant. The practical move is to turn the effort dial up first. It costs nothing to configure, moves the metric more than picking a different model in most cases, and most users leave it on the default.
Three patterns in failed runs
In low-recall runs (recall well below 50%, sometimes below 20), one move keeps showing up. The agent stops gathering evidence before its own evidence supports stopping. Three sub-patterns recur, often two at once in the same failed episode.
1. Premature confidence in early signals
The agent runs a search, gets back a list of filenames that contain matches, and treats the list as the answer. Files in the list that the agent never opens still end up in the final answer.
From a Claude Sonnet 4.6 (low) run on a Red Dead Redemption 2 article (final recall: 5%):
- Grep
- pattern="red_dead_redemption_2|Red Dead Redemption 2"
- Result
- (26 files matched)
- Grep
- pattern="Arthur Morgan|Van der Linde|Rockstar Games.*1899|Red Dead Online|..."
- Result
- (8 files matched, 2 new: 2330.md, 4846.md)
- Bash
- cat 2330.md 4846.md (2 files opened in full)
- Final
- "Here are all 28 files that belong to the article..." (28-file list submitted, 26 of them never opened)
The reasoning between the two reads and the submission was a single line. “These two files also belong to the article. Let me compile the full list.” The agent confirmed the two new hits, then jumped from “two confirmed” to “all 28 confirmed” without verifying the other 26.
2. Narrow search vocabulary
The agent’s keywords are anchored too tightly on the proper nouns in the prompt. Target passages that refer to the subject by a different form, for example a surname after first introduction, never appear in the search results. The agent doesn’t try alternative vocabulary before stopping.
From a Codex GPT-5.4 mini (low) run on a Bob Feller biography (final recall: 32%):
- rg
- pattern="Bob Feller|Robert Feller|Rapid Robert"
- Result
- (27 files matched, but 32 target passages refer to the subject as plain "Feller" and never surface)
- sed
- for f in <those 27>; do sed -n '1,1p' ${f}.md; done (one-line previews to triage)
- Final
- 16-file list submitted (recall caps at 32% — bare-token "Feller" search never tried)
The 32 target passages this run missed all referred to the subject as “Feller” without a first name (Wikipedia style: full name on first reference, surname after). A rg -li "Feller" search would have surfaced almost every one. The agent never tried it. The stop framing was “I’ve narrowed it to the passages that actually advance Feller’s biography,” a precision question over the closed 27-file candidate set rather than a recall question about whether to keep looking.
3. Stated-but-skipped verification
The agent says what its next step will be, then submits the final answer without doing it. The trace contains an explicit plan that never fires. The agent contradicts its own stated intent inside a single LLM turn.
From a Codex GPT-5.4 (low) run on a Stikine River article (final recall: 35%):
- Grep
- pattern="Stikine|Tahltan|Stikine Country|Wrangell|..."
- Result
- (49 files matched)
- Plan
- "I have a candidate set of 49 files. Next step is to read them in bulk and drop any passages that only mention the Stikine incidentally rather than belonging to the article."
- Final
- 49-file list submitted immediately (no bulk read happens)
The common thread
In all three patterns there is a clearly visible next step that would help, and the agent skips it. For pattern (1) the next step is opening the candidate files. For pattern (2) it is trying a different keyword set. For pattern (3) it is doing the verification the agent itself just said it would do. Different surfaces, same shape. The agent stops one step before its own evidence supports stopping.
How often does this happen? Counting episodes with recall under 70% per variant:
| Variant | Episodes recall < 70% |
|---|---|
Codex GPT-5.4 (max) | 0 / 60 |
Codex GPT-5.4 (low) | 4 / 60 |
GPT-5.4 mini (max) | 4 / 60 |
GPT-5.4 mini (low) | 17 / 60 |
Opus 4.6 (max) | 0 / 60 |
Opus 4.6 (low) | 1 / 60 |
Sonnet 4.6 (max) | 0 / 60 |
Sonnet 4.6 (low) | 13 / 60 |
Both flagships at max effort never fall into the pattern. GPT-5.4 mini and Sonnet 4.6 at low effort fall into it in over a fifth of episodes. The difference between strong and weak runs is whether the agent takes the next step that its own trace makes clear is still needed.
What this tells us
Exploration shapes the rest of the work, and each agent does it differently. The flagship models (GPT-5.4 and Opus 4.6) both reach about 95% recall on the same task, but take different paths in cost, reasoning effort, and per-call context. Each has its own explorative policy, so picking between them on exploration alone is a choice between trade-offs.
Weaker models in each family explore worse. More than one in five low-effort Sonnet 4.6 and GPT-5.4 mini runs fall into the recurring failure mode where the agent stops one step before its own evidence supports stopping. The same kind of premature stopping shows up as incomplete edits and missed context on real coding tasks.
Two caveats. The corpus is Wikipedia passages, not source code. We sampled four models from two families at two effort settings, and the messier parts of real coding (user clarifications, multi-step plans, write-side failures) are not in this setup.
Contributions
Writing by Minseung Lee and Remy Kim. Experiment design, analysis, and figures by Minseung Lee.
OpenAI, Codex, Claude, and Claude Code are trademarks of their respective owners. Logos appear here for identification only. This is independent comparative research, and no endorsement or partnership is implied. The mascot figures (cloudling and clawd) are from clawd-on-desk and are not official mascots of OpenAI or Anthropic.